Pass-Through vs. Sync-Based Unified APIs: Architecture Tradeoffs Explained
March 30, 2026
Most unified API platforms look the same on the surface. They all promise a unified API across dozens of integrations, normalized schemas, and faster time to market.
Under the hood, they are built on two very different architectures.
A pass-through unified API executes every request directly against the source system in real time. A sync-based unified API copies third-party data into its own database and serves reads from that stored replica.
Both approaches can provide the same endpoints. They produce very different behavior once your product is in production.
Why this distinction matters
Two platforms can both return data from /crm/contacts. One is returning live data from the source system. The other is returning a cached copy from a background sync.
That difference affects:
- whether your product reflects current state
- whether workflows execute correctly
- whether users trust what they see
- whether AI systems produce accurate outputs
This is not an implementation detail. It defines how your product behaves.
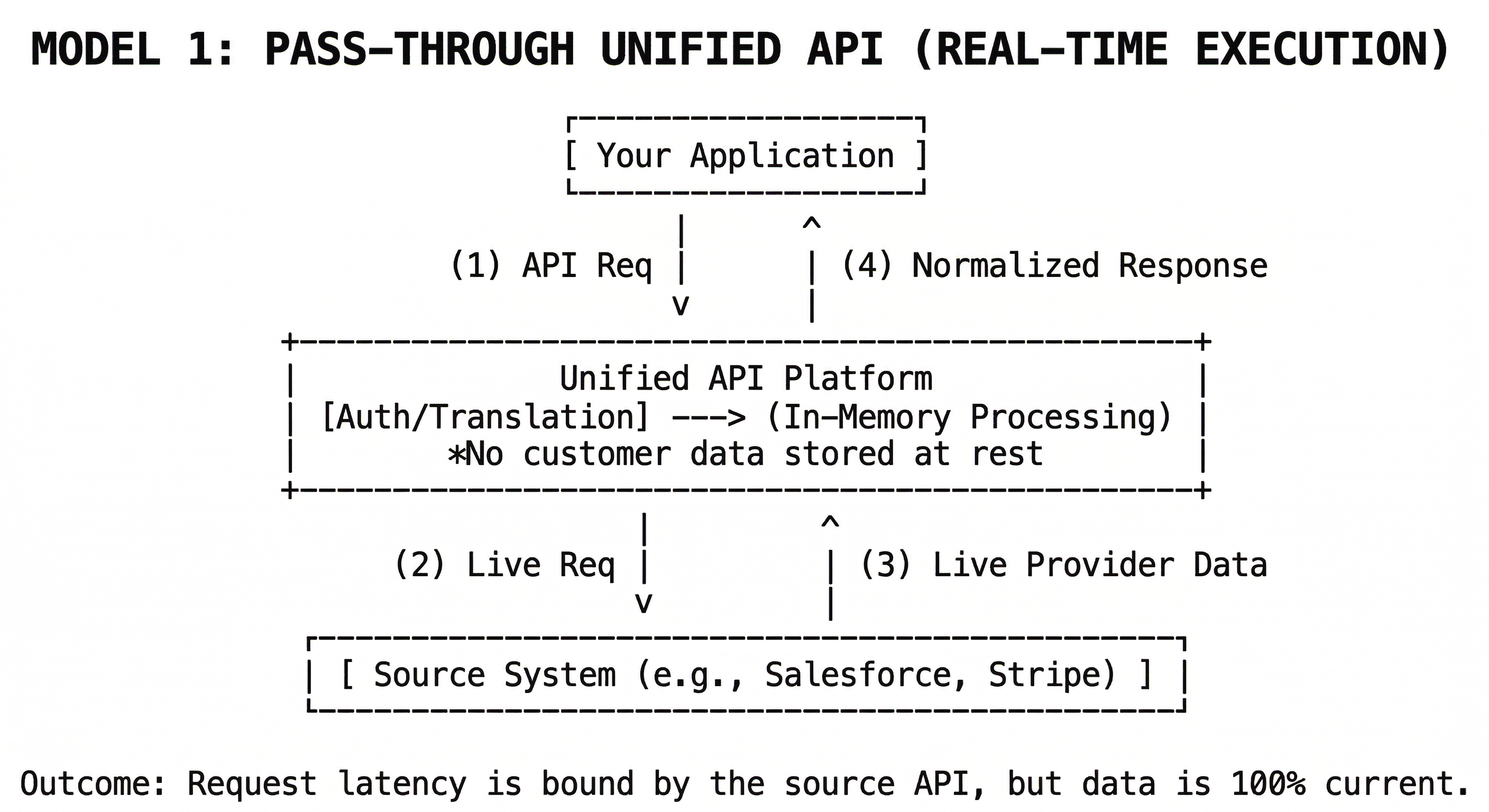
What is a pass-through unified API?
A pass-through unified API is a real-time execution layer.
When your application makes a request:
- the platform authenticates the request
- retrieves connection credentials
- translates the unified request into the provider's format
- calls the upstream API directly
- normalizes the response in memory
- returns the result immediately
No customer data is stored as a system of record.
What this means in practice
- reads come directly from the source system
- writes go directly to the source system
- responses reflect current state
- transformations happen at request time
- latency depends on upstream APIs
This model prioritizes correctness and real-time behavior.
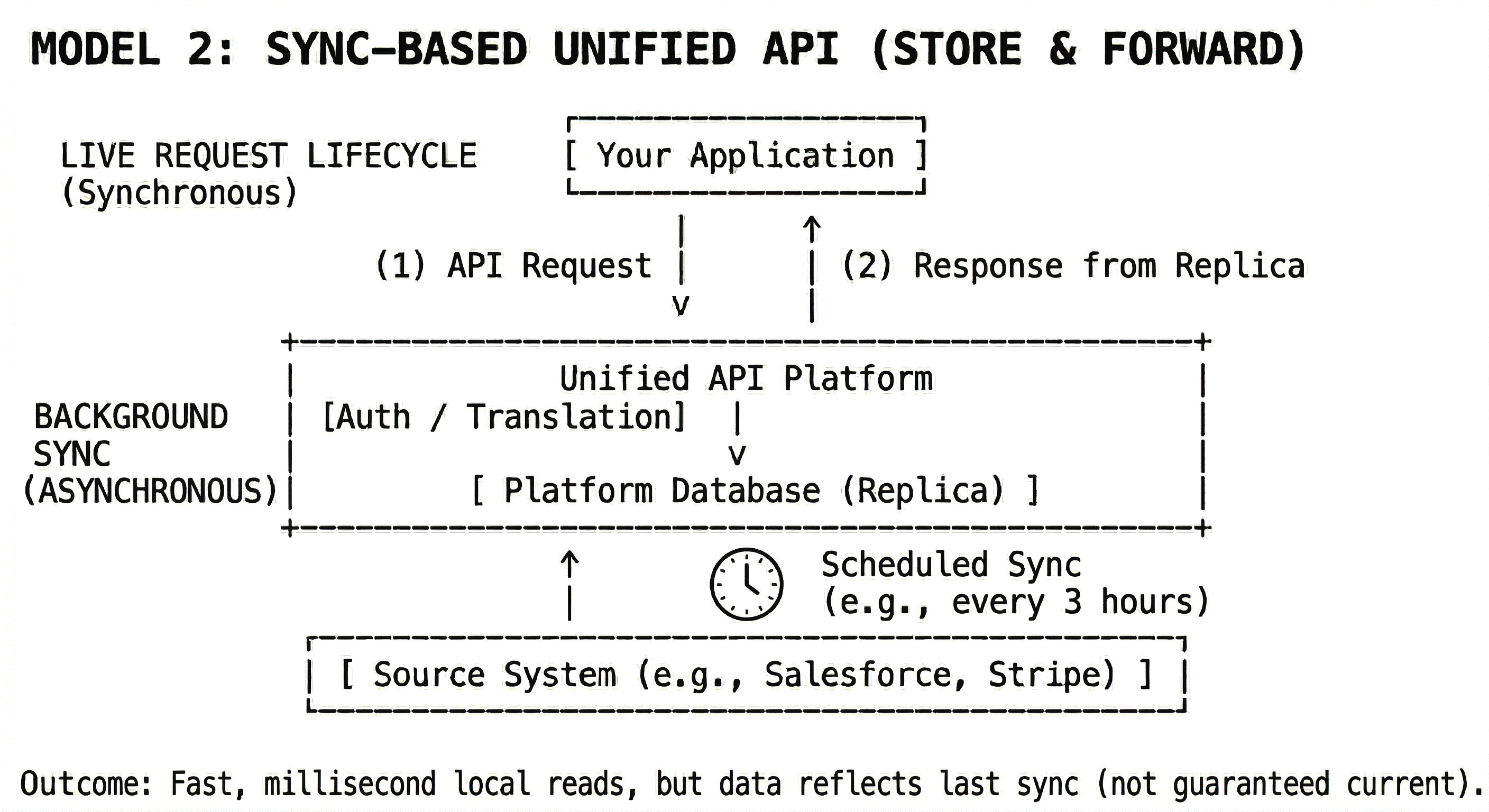
What is a sync-based unified API?
A sync-based unified API uses a replication model.
Instead of fetching data on demand, the platform:
- polls upstream APIs on a schedule
- retrieves data in batches
- normalizes it
- stores it in its own database
- serves API responses from that stored copy
What this means in practice
- reads come from the platform's database
- writes still go to the source system
- data freshness depends on sync frequency
- background jobs manage pagination, retries, and rate limits
This model prioritizes speed and availability for reads.
Side-by-side comparison
| Dimension | Pass-through | Sync-based |
|---|---|---|
| Read source | Live upstream API | Internal database |
| Write path | Direct to upstream | Direct to upstream |
| Data freshness | Real-time | Delayed (minutes to hours) |
| Latency | Network-bound | Fast local reads |
| Read-after-write consistency | Strong | Often inconsistent |
| Failure mode | Depends on upstream | Can serve stale data |
| Rate limits | Exposed downstream | Managed internally |
| Event delivery | Real-time (native or virtual) | Sync-triggered |
| Compliance scope | Minimal | Expanded (stores data) |
| Infrastructure complexity | Lower | High (sync engines, queues) |
| Best for | Workflows, automation, AI | Reporting, analytics |
The tradeoffs that actually matter
Data freshness vs. speed
Sync-based systems are faster for reads because they query a local database. The tradeoff is that the data may be outdated.
Pass-through systems are slower because they depend on upstream APIs. The tradeoff is that the data is accurate at the moment of the request.
The real question is not speed. It is whether your product needs current state.
Read-after-write consistency
This is where many teams run into problems.
In a pass-through model:
- you update a record
- you read it immediately
- you see the updated value
In a sync-based model:
- you update a record
- the sync has not run yet
- you read stale data
This creates inconsistencies in:
- user interfaces
- approval workflows
- automation logic
Event delivery and product behavior
Sync-based platforms typically emit events after a sync completes. That introduces delay and often requires follow-up API calls to fetch updated data.
Pass-through platforms simulate real-time behavior using virtual webhooks:
- changes are detected via polling
- full records are delivered immediately
- no additional fetch required
This changes how you design product features. It determines whether your system reacts instantly or eventually.
Compliance and data storage
Sync-based platforms store customer data. That expands:
- audit scope
- data residency requirements
- breach surface area
Pass-through platforms avoid storing payload data. That reduces:
- compliance overhead
- vendor risk
- duplication of sensitive data
For enterprise teams, this alone can influence vendor selection.
Behavior under failure
Sync-based systems can continue serving stale data if the upstream API is unavailable.
Pass-through systems reflect upstream availability directly. If the source API is down, requests fail.
This is a tradeoff between:
- availability
- correctness
Different products prioritize this differently.
AI and real-time systems
AI systems depend on current data.
If your architecture feeds stale data into:
- copilots
- agents
- retrieval pipelines
you introduce incorrect outputs and broken workflows.
Pass-through architectures align better with:
- real-time context
- deterministic behavior
- synchronous read/write loops
Where unified API vendors fall
Most vendors cluster clearly by architecture.
Pass-through / real-time execution
- Unified.to
- Apideck
- Truto
Sync-and-store
- Merge.dev
- Rutter
- Codat
- Finch
Hybrid / infrastructure-oriented
- Nango
- Paragon
This classification is more useful than feature lists. It tells you how the system behaves.
Why vendors in the same category are still different
Even within pass-through architectures, platforms are not interchangeable.
They differ in:
- depth of schema coverage
- event delivery design
- support for custom fields and objects
- passthrough flexibility
- category breadth
- pricing model
- AI and agent support
For example:
- Apideck focuses on providing a clean abstraction layer across common integration categories
- Unified.to extends the same architecture into real-time execution, event delivery, and multiple consumption patterns including webhooks and MCP
The architecture defines the baseline. The product surface defines what you can build.
Why some platforms introduce hybrid models
No single architecture optimizes for both real-time execution and high-volume querying.
That's why some platforms introduce hybrid approaches that combine:
- real-time API execution
- scheduled data storage
This is typically done to support:
- analytics use cases
- repeated queries over large datasets
- historical reporting
The tradeoff hybrid introduces
Hybrid models do not eliminate the tradeoffs. They combine them.
In practice, this means:
- part of your product runs on live data
- part of your product runs on stored data
That creates two sources of truth.
You now need to reason about:
- when data was last synced
- whether a response is live or stored
- how inconsistencies are handled
When hybrid makes sense
Hybrid architectures are useful when:
- you are building reporting or analytics features
- you need to query large datasets repeatedly
- strict real-time behavior is not required across all features
When hybrid creates problems
Hybrid becomes problematic when:
- your product depends on current state
- you are building automation or decision logic
- consistency between reads and writes matters
In these cases, mixing stored and real-time data introduces edge cases that are difficult to debug.
What most product teams actually need
Most product-facing features depend on:
- current state
- deterministic behavior
- immediate consistency after writes
That aligns more directly with real-time execution models.
Storage can still exist—but it should be:
- intentional
- controlled
- separate from your integration execution layer
How to choose the right architecture
Choose pass-through if:
- your product depends on current state
- you are building workflows or automation
- read-after-write consistency matters
- you are building AI features
- you want to reduce compliance scope
Choose sync-based if:
- you need fast repeated reads
- you are building dashboards or reporting
- some data staleness is acceptable
- you want insulation from upstream outages
Choose hybrid if:
- you need both real-time accuracy and high-volume querying
- you want execution and storage separated
Building with a real-time execution model
Unified.to is built around the pass-through model, with extensions that address the limitations teams typically encounter.
- requests are routed directly to source APIs in real time
- no customer data is stored at rest
- native and virtual webhooks enable event-driven behavior
- custom fields and objects are supported without schema lock-in
- passthrough allows direct access to provider-specific endpoints
- the same models power API, webhooks, database sync, and MCP
This architecture supports:
- real-time product behavior
- automation workflows
- AI-driven systems
without introducing a secondary data layer.
Key takeaways
- Pass-through unified APIs execute requests directly against source systems in real time
- Sync-based unified APIs serve data from stored replicas
- The tradeoff is accuracy versus cached performance
- Pass-through is better for workflows, automation, and AI
- Sync-based is better for analytics and high-volume querying
- Most teams will need elements of both, but should be deliberate about where data is stored and why
This decision shapes how your product behaves in production. Choose the model that aligns with what your product actually needs to do.